Retrieval-Augmented Generation
Overview
Retrieval-Augmented Generation (RAG) is a powerful technique that enhances the capabilities of large language models by combining them with an external knowledge base. Instead of relying solely on the model’s pre-trained parameters, RAG retrieves relevant passages from a curated collection of documents and integrates them into the response generation process.
In Arcanna, RAG enables semantic search across your uploaded content, ensuring that the Assistant can access the most accurate and contextually relevant information at query time. This allows for dynamic, knowledge-grounded answers that evolve as your collections grow.
The assistant can use RAG to semantically search through collections of documents that the user uploads in Arcanna.
Why RAG
Using RAG offers several key benefits:
- Efficiency in Token Usage: Instead of uploading entire documents—which could waste tokens on irrelevant sections—you only retrieve and use the specific passages relevant to your query.
- Up-to-Date Knowledge: You can continuously update collections with new documents, ensuring the Assistant always has access to the latest information.
- Domain Customization: Tailor the Assistant to your unique datasets and knowledge base without retraining a model.
- Improved Accuracy: By grounding responses in your actual content, RAG minimizes hallucinations and increases factual reliability.
- Scalability: Large collections can be segmented into smaller, organized sets, making search more structured and manageable.
Collections
Create a Collection
- Navigate to MCP Tools Menu → RAG Collections
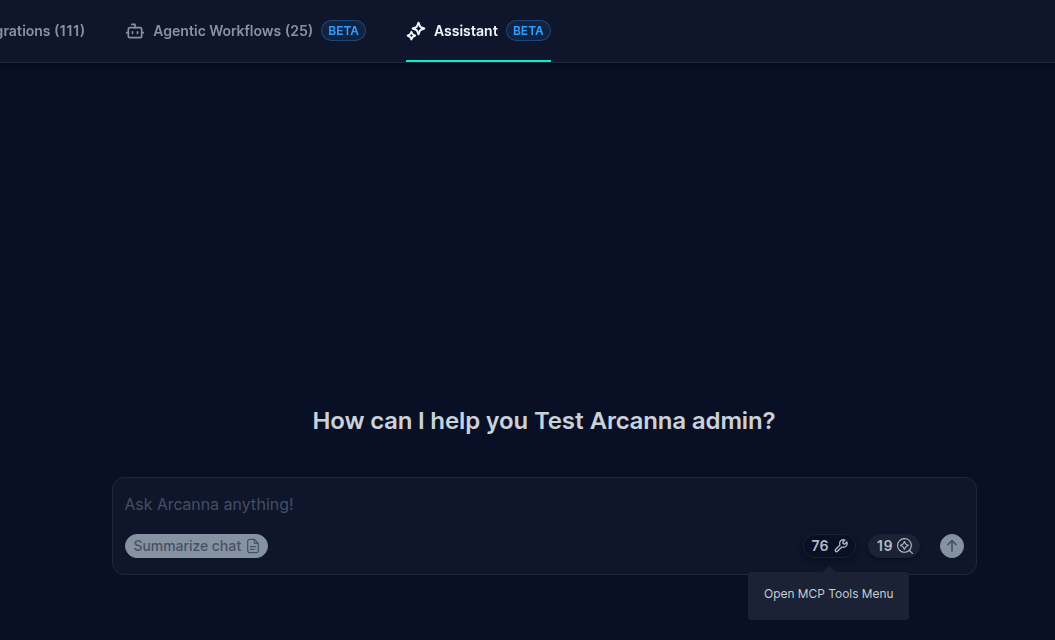
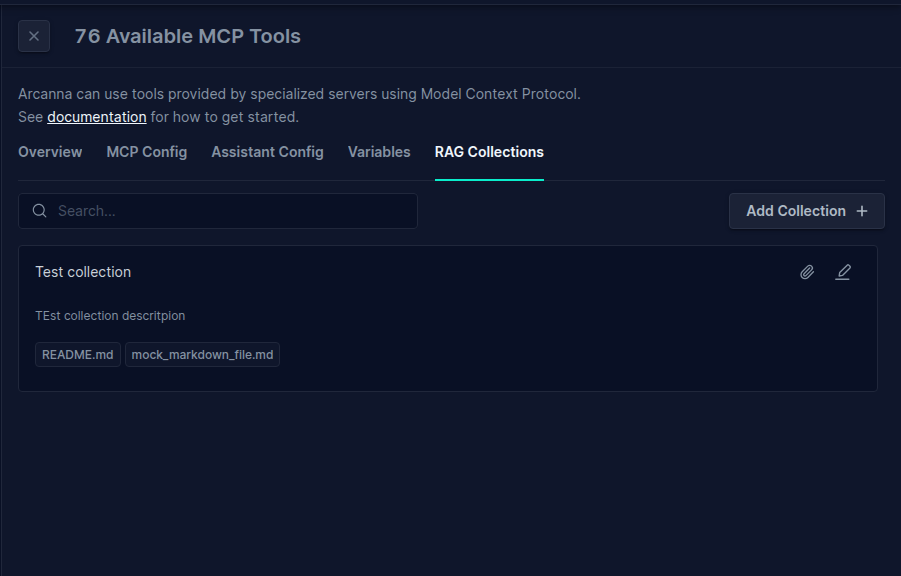
- Click on Add Collection (+)

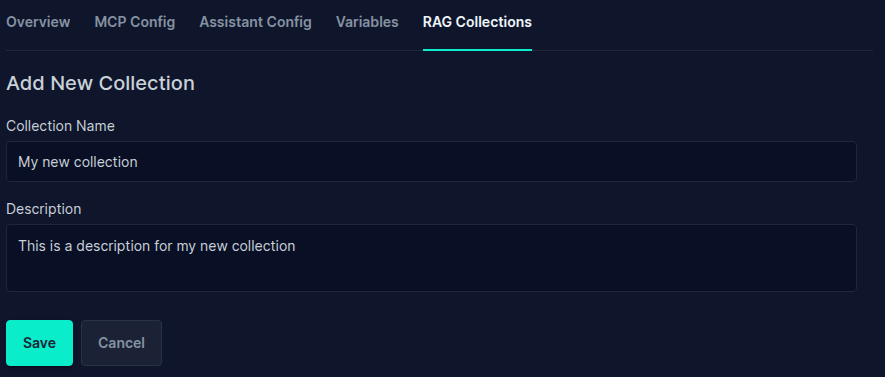
- Provide a name and description for your collection and Save
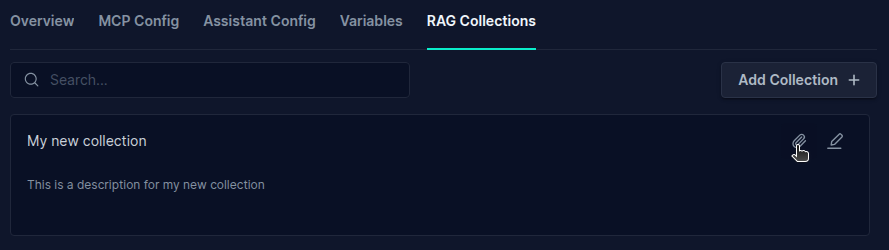
Insert a Document into a Collection
- Click on the Attachment Icon
- Select a
.mdfile from your computer- (Currently, only Markdown files are supported. Support for additional formats will be available in future updates.)
- (Currently, only Markdown files are supported. Support for additional formats will be available in future updates.)
- Click on the Disk Icon to upload the file
Search the Collection with Arcanna’s Assistant
You can now query the collections you uploaded by directly instructing the Assistant to search within them.
If no collection name is provided, the Assistant will search through all available collections by default.
If you need broader context around your query, specify a higher retrieval_level (greater than 5). The default retrieval_level is 5.
Markdown file guideline
In order to have the best possible results here is a list of best practices to format your file.
1. Markdown file should start with a header
Your markdown file is split in headers. Each text that belongs to a header is then split in chunks and vectorized.
If, for example, your file starts with:
Information about something
### Overview
...Overview information
The line "Information about something" will not be vectorized and therefore will never be retrieved.
2. Use meaningful headers
Ensure each section starts with a clear and descriptive header (e.g., ### Overview, ### Setup Guide, ### API Usage).
This improves retrieval precision, as queries will map more effectively to semantically meaningful sections.
3. Keep sections concise
Try to avoid overly long sections under a single header.
If a topic is broad, break it down into multiple headers and subsections. This makes retrieval more accurate and prevents pulling large, irrelevant chunks.
4. Avoid unnecessary formatting in raw text
While Markdown styling (bold, italics, lists) is helpful for humans, keep content clear and avoid clutter with excessive symbols or repeated formatting.
This ensures vectorized content stays clean and semantically strong.
5. Use consistent terminology
If a concept has a specific name in your domain (e.g., input integration in Arcanna), always refer to it using the same term across the document.
Inconsistent phrasing may fragment search results and reduce relevance.
6. Keep content factual and self-contained
Write sections so they can stand alone if retrieved.
Avoid saying things like “as mentioned above” or “see below,” since retrieval may not include surrounding context.
7. Prefer bullet points and lists for clarity
Where possible, use lists to structure key points, instructions, or parameters.
This improves both readability and retrieval accuracy.
8. Avoid very large files
While Arcanna can handle large collections, splitting oversized files into multiple smaller, thematically organized Markdown files will improve indexing and retrieval performance.